Part 2: What Is CloudStore?

Start using Visor today
- Visualize all your projects and data

- Roll up multiple projects into portfolio views
- Try Visor for FREE
In Part 1, I shared how a unique technical challenge drove us to build a datastore framework that synchronized state. In this post, I’ll share how CloudStore works.
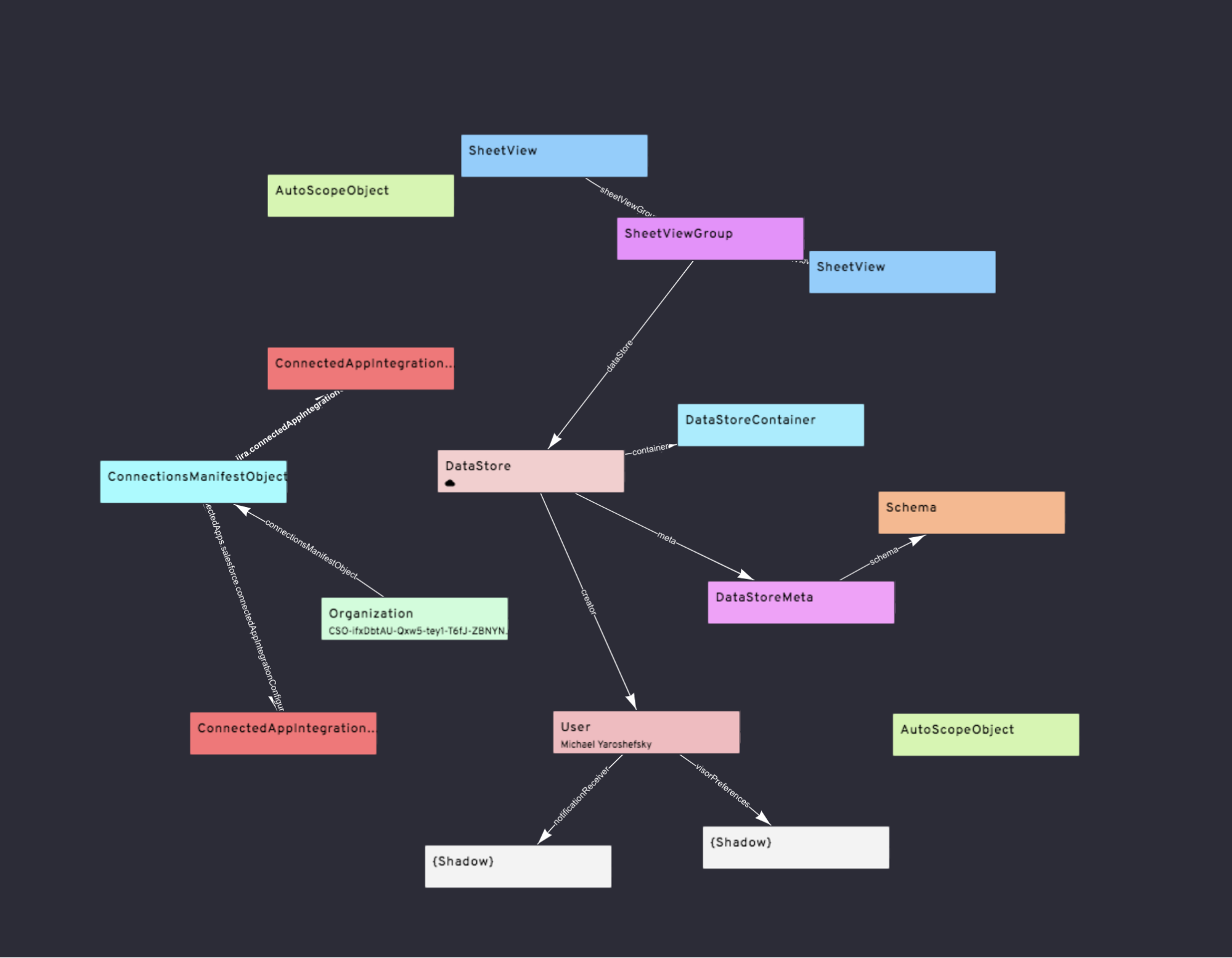
CloudStore is a realtime graph database synchronized between our server and our web clients. The entire graph (consisting of nodes and edges) is our distributed global state, storing information about our user’s workbooks, their sheets, the rows, etc.
The server maintains the authoritative copy of the graph. On each client, we load down just the nodes and vertices necessary to render the UI. We call this a loaded subgraph. Using VueJS as our UI framework, the interface is driven directly from the global state.
Objects in the Graph
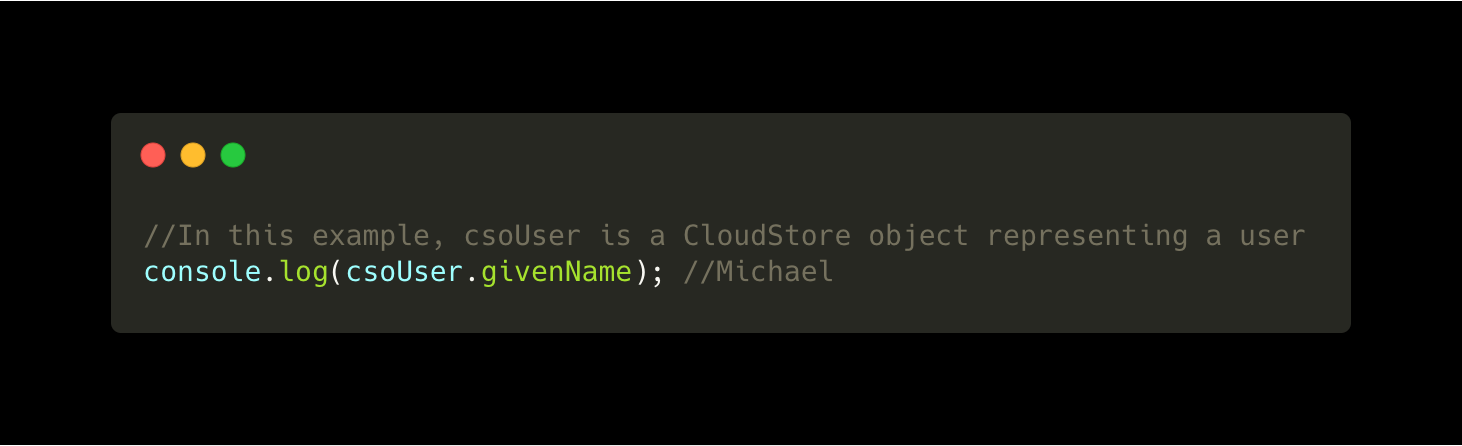
Nodes in the graph represent things like users or workbooks. We call them CloudStore Objects, because they’re just JavaScript objects wrapped in proxies.
Reading a property from a CloudStore Object is straightforward:
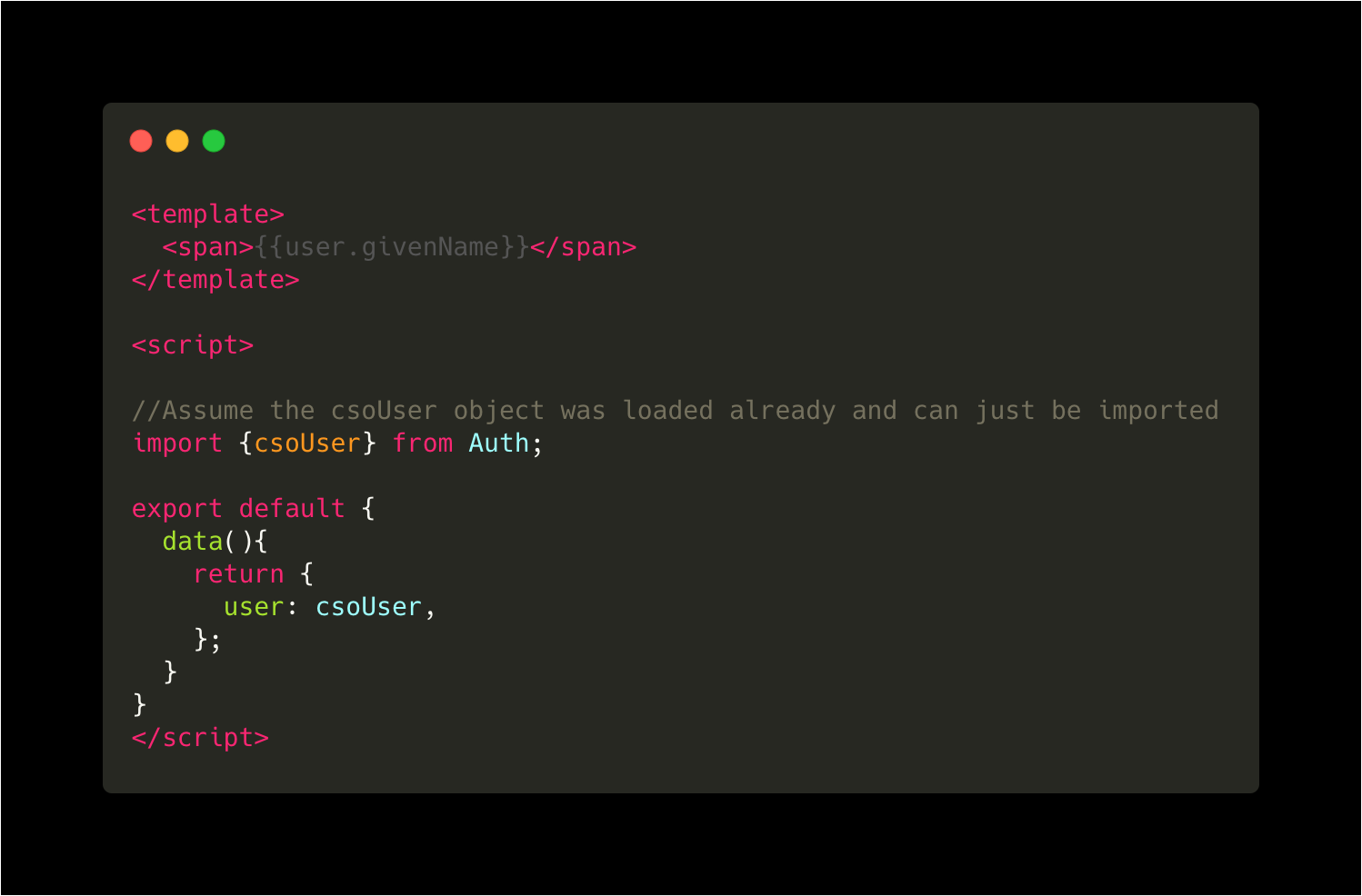
CloudStore objects can generally be treated just like regular JavaScript objects. Creating interfaces in Vue that directly bind to data in a CloudStore object is straightforward:
Edges in the Graph
Edges represent relationships between objects, such as linking a user to a workbook she created. Edges are directed (meaning they have a ‘from’ object and a ‘to’ object). Nonetheless, the subgraph can be loaded from the server by following edges in either direction. The client code can also traverse the subgraph following edges in either direction, but it’s easier to follow edges outbound from an object.
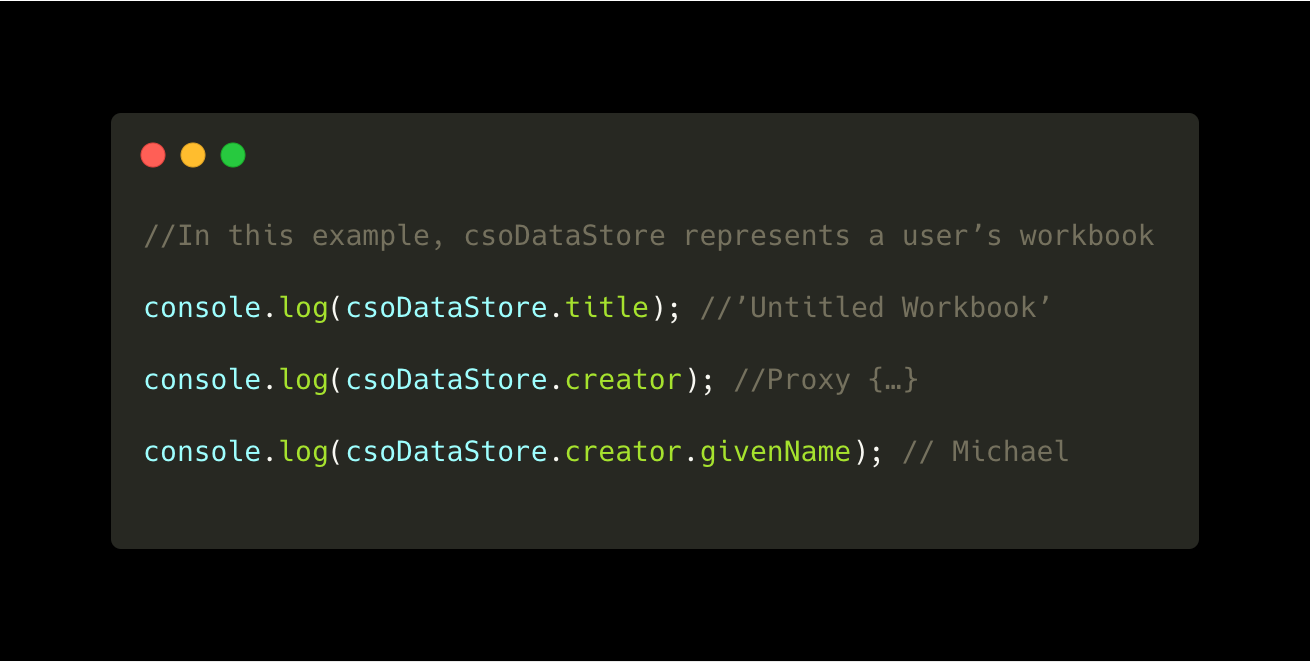
For syntactic convenience, edges can be traversed in the outbound direction via the normal dot operator in JavaScript. In the example below, we can traverse the ‘creator’ edge between a DataStore object and the User object to print the creator’s given name.
This preserves the original intention of making the syntax of working with these synchronized objects as natural as working with ordinary JavaScript Objects. In doing so, we keep a lot of the complexity out of the more hastily-written UI code.
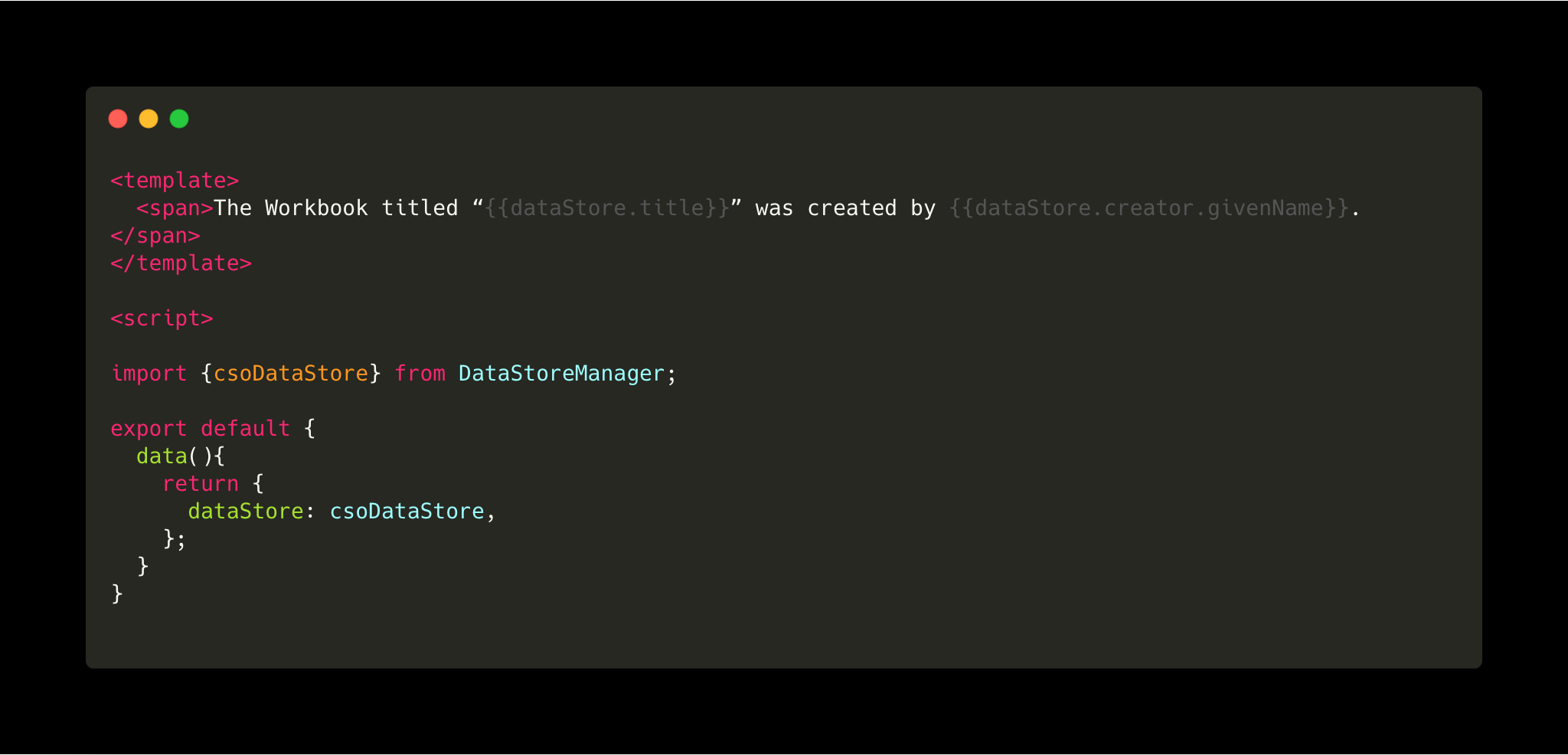
In Vue, here’s an example of printing the creator’s given name by traversing the subgraph directly in the template.
Object Types
To maintain data integrity, objects are assigned types, and each type has a defined schema. These schemas declare the properties that are allowed on these objects, including data type and value validation.
The object type definitions also define the edges that are legal. All edges require double-opt-in: both the originating and the terminating object of a directed edge must approve the edge set for it to take effect. Illegal edge set attempts will fail at runtime.
Object type schemas allow the definition of class methods for mutations to these objects. As a design pattern, we only perform mutations via these methods, rather than directly mutating the objects in UI code. So, for example, a DataStore object has a method for adding a new Record. The UI code just calls this as a one-liner in the components where this is needed. This is similar in principle to how certain frameworks, like Vuex, factor out changes into mutations that can be called.
We also implemented our own inheritance scheme for these types. For example, our User object type inherits properties and methods from a Person type (e.g. givenName, familyName) while adding certain other properties and edge permissions needed for a user (e.g. the user identifying GUID). Person inherits from Entity, and so on.
This has some benefits for the DRY principle, and in the past we used this capability as one would use an interface: certain code could handle objects of various types, as long as they inherited from some base object. But it does strike me now as a bit of overengineering.
Working with something off the shelf, like Typescript, seemed like unnecessary overhead for something easily achieved with a few ‘if’ statements in the proxy handlers we already had. Typescript also would not help with the validation we needed for graph operations such as creating new edges between objects. While there was much to be learned from Typescript, it wasn’t an apples-to-apples comparison for our actual needs.
Patches and Synchronization
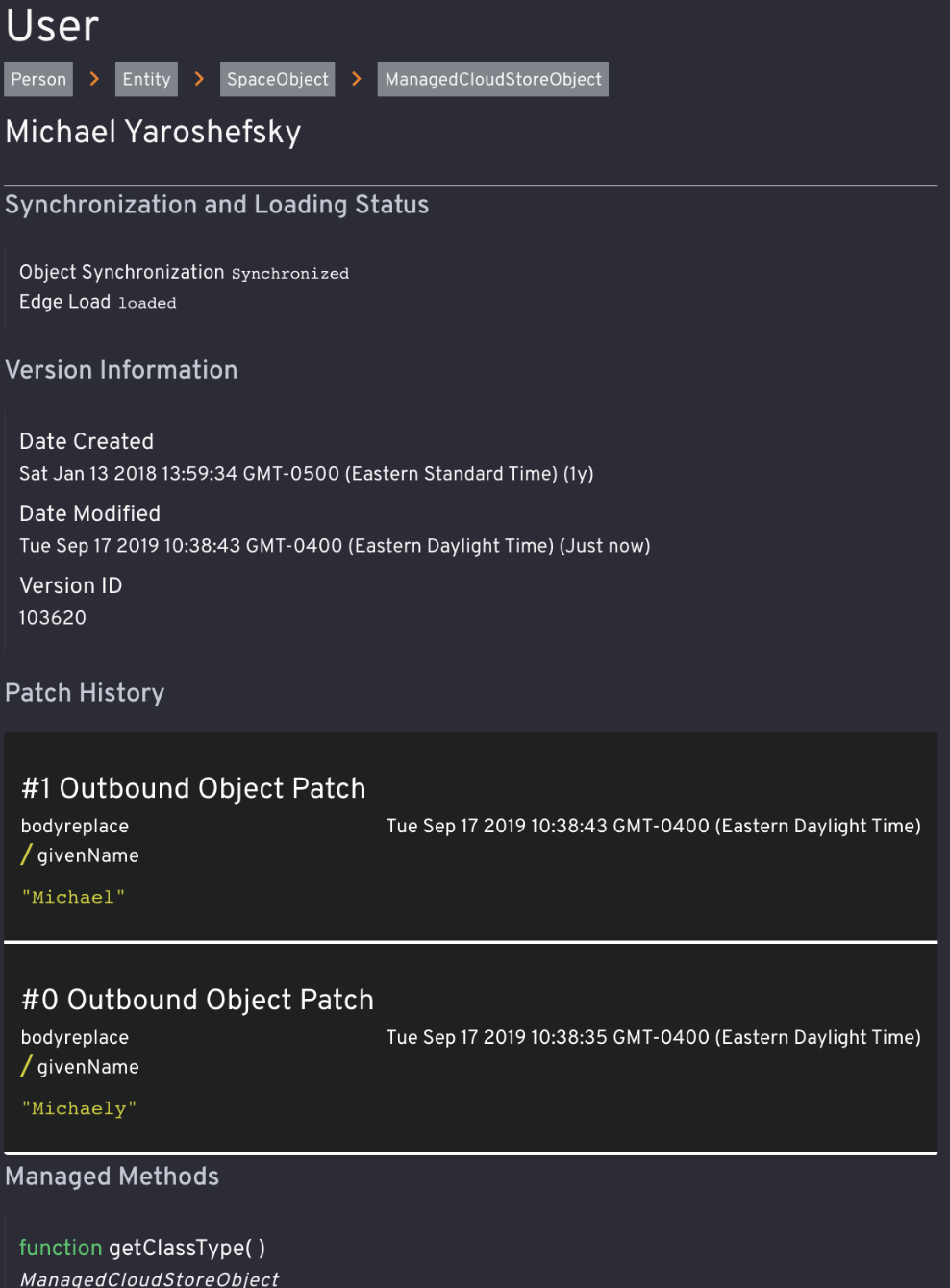
Changing a property on a CloudStore Object is identical to doing so on a regular JavaScript object. This change will be synchronized with the server and then syndicated to all other instances of this object on other devices. As we pass around these mutations, we represent them as JSON patches according to RFC 6902.
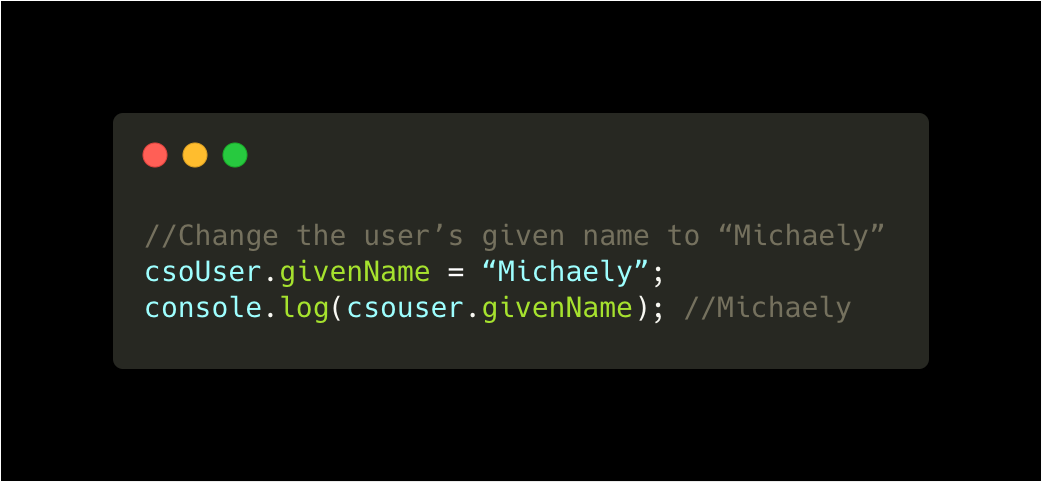
Changes made locally by the user via the UI are applied directly to the client-side subgraph, causing Vue to re-render immediately. Synchronization then occurs later, after the UI has updated. This provides major advantages over another common way of building web apps, where user actions must first be confirmed on the server before the UI can progress.
Adding Objects to the Graph
Changes that get synchronized may also be more complicated than just changing properties. Creating entirely new objects and linking them to one another will generally cause clients with the second object to need to be informed about the creation and linking to the other object. An example of this is creating a row in a table and attaching it to the object representing the table it belongs inside, like this:
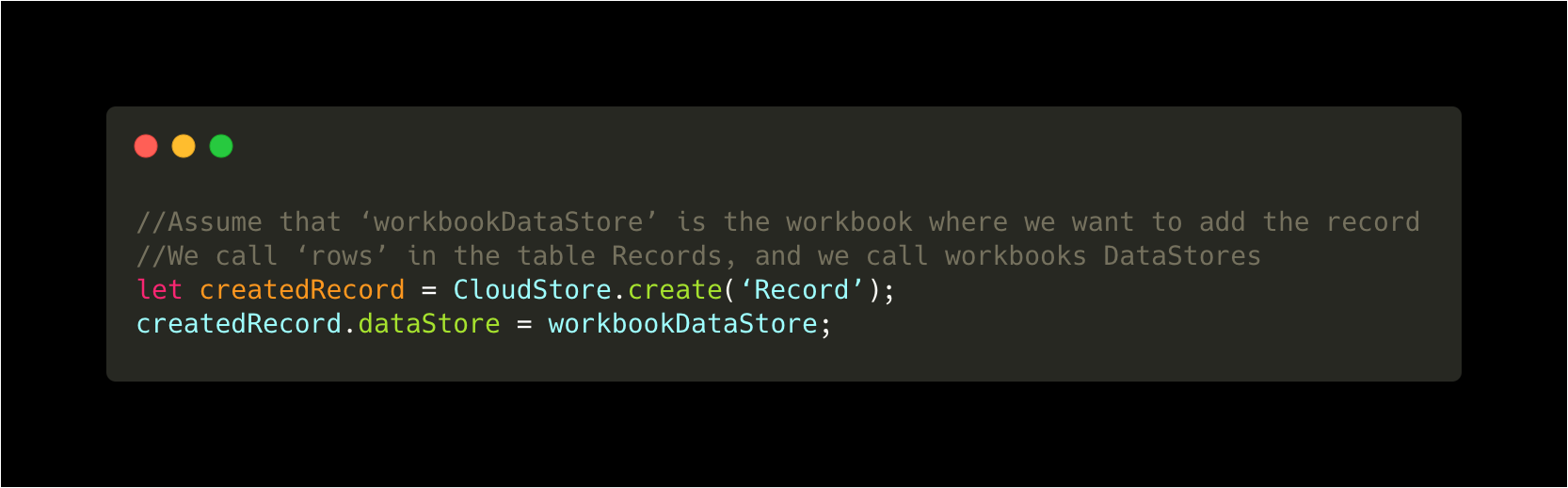
When this edge is created, any clients with the “DataStore” object loaded locally will be informed automatically about the new Record.
By relating the Record and the DataStore object in this way, we’ve created a one-to-many relationship between Workbooks and Rows, which is by design. Each Record may only belong to one DataStore, but each DataStore may have any number of Records pointing edges into it.
Synchronization logic
Client-side changes are asynchronously sent to our server for storage and processing. This is an optimistic way of saving information; we can generally assume that a synchronization will succeed, and the user does not have to wait for synchronization to continue. Synchronization failures are presented to the user as soon as they are known.
The server maintains knowledge of what subgraph each client has loaded so that changes made by other clients can be sent to the subscribed clients that are impacted. These updates are communicated via websocket messages.
Patches arriving inbound to a client are applied to the impacted objects or edges in the subgraph. If these changes affect a Vue dependency, Vue automatically re-renders the UI components impacted. In this way, the entire interface is synchronized over the network automatically via the global state graph.
We currently save every version of an object or edge, creating a new complete snapshot every time a change arrives. We also record a substantial amount of metadata associated with each change, providing clear audit trails of how the subgraph changed. This allows us to rewind certain changes during development, and it gives us confidence in being able to safeguard customer data.
Triggering server operations (implicitly)
While CloudStore reduces the amount of server-side code needed for new features, it doesn’t eliminate it entirely. Some bulk operations are best done by the server to reduce client load.
For example, when a user deletes a column in Visor, we need to go through all of the records in that workbook and delete the values in that column. We didn’t want to rely on the clients for this bulk operation, in case they got interrupted before dispatching all of them (e.g. by the user closing the tab). While each object’s mutation is atomic, we’ve yet to build a system for running multiple mutations of the graph atomically together.
We wanted to come up with a way to accomplish this that felt natively CloudStore in the syntax and didn’t introduce the need for loading screens which we’d been able to avoid so far. (Some operations do need loading screens, and we have another explicit way to trigger those operations, which I’ll describe in the next section).
A hybrid solution — updating CloudStore with the immediate change and then triggering a bulk operation using Ajax calls — seemed like a potential source of problems if they didn’t both succeed.
The solution we came up with is a system that observes the creation and mutation of CloudStore objects and edges and, when certain criteria about the mutation are matched against a list of these we maintain on the server, it triggers a specific server-side handler. We call this Object Post Processing Instructions (OPPI) for when an object creation, modification, or deletion is the trigger and Edge Post Processing Instructions (EPPI) for when the creation, modification, or deletion of an edge is the trigger. This architecture makes use of Redis and Celery so that this post-processing can be done asynchronously after the ajax-based operation that triggered it returns to the client. The handlers for these are generally AWS Lambdas.
The flow is roughly like this:
- On the server, an operation mutates the CloudStore graph
- Asynchronously, the mutations are compared against a list of registered post-processing handlers
- All matching post-processing handlers are invoked, typically calling an AWS Lambda
- The Lambdas may modify the CloudStore graph further, committing operations to CloudStore
- Any modifications are sent to all clients subscribed to changes to these objects or edges
In the case above of removing a column in Visor’s table view, deleting a column from the Schema object automatically hides the column in the UI for the user, but column data remains in all of the Records. To clean up this data, deletion of the column from the Schema object matches a registered OPPI. This triggers a Lambda that follows the graph from the Schema object through to the root DataStore and then to all of the attached Record objects. The Lambda then modifies each of these records accordingly, removing values in the deleted column and saving these changes. Server side changes to CloudStore objects also synchronize with clients, so the Record objects in the client all get updated as well.
This has worked well for our needs so far, but the main downside is it reduces the explicitness of our code that relies on this. It’s not obvious that certain client side mutations will cause server operations that may, in turn, update client side state again. We don’t yet have a great solution to this other than shared knowledge of what changes trigger these operations. There aren’t that many of them, and we’re a small team, but we’ll be looking for a better system as we grow.
Triggering server operations (explicitly)
While the above solution generally does not provide status to the user as it is processing, some long-running server operations do need to communicate state to the user. For example, our synchronization with Jira is designed to show progress to the user. These can take upwards of a few seconds depending on the response time of Jira and the number of synchronization tasks.
In this case, we created a pattern of explicitly creating CloudStore objects called Operation Request Objects (ORO) that trigger post-processing. The OROs themselves contain within their JSON payload all of the parameters necessary to carry out the operation. They run through a dispatching system on the server to reach the correct handler method.
This seemed like a good way to trigger these operations, but how do we communicate status back to the user?
Eventually we realized that the OROs could also be updated with the result, which would be synchronized back to the client that created it. In this way, the ORO contains both the instructions for what to do on the server and the results of that operation.
For example, when a user clicks the “Sync” button in our product to synchronize with Jira, we create an ORO that contains instructions about what to sync. The server saves the ORO like a normal CloudStore object, but then the OPPI (described in the section above) dispatches the OROs to a routing handler which reads inside the ORO to determine which service should be called to handle this ORO. The object is transferred to the service that executes the ORO. As the executing service proceeds, it pushes a standard set of status updates into an array inside the ORO. The client will see this synchronized, and it’s trivial to bind a Vue UI to this status array. When the final result is known, a boolean flag on the ORO is set to mark completion and the result is set inside a special place in the ORO to be read by the client. There is a protocol for setting error and warning messages as well.
This has a few interesting advantages. One is that when an ORO is created that affects a Workbook, an edge connects the ORO to the DataStore object representing the workbook. Because the graph synchronizes this new edge to other clients, they’ll all become informed about the processing operation. This allows every user with the workbook open to see the status of the operation in progress. Another advantage is with auditing, where each of these “calls” to the server automatically provides an auditable trail.
The main disadvantage of this system is time and overhead. Creating CloudStore objects vs. just calling out to a server incurs some additional overhead. This is also a complicated system of recognizing, dispatching, and routing these operations. That introduces more points of failure. We’ve spent too much time than I’d like to admit trying to figure out where an ORO failed to reach its final processing point. But now that the kinks are worked out, the system provides a good user experience and a useful audit trail.
The stack
Under the hood, our server side architecture includes:
Amazon ElasticBeanstalk + Postgres on RDS. The choice to use Postgres came down to our familiarity with using Postgres in previous Django projects, and JSONB seemed sufficient for our needs when we began. If we started over, we might consider a native NoSQL solution like MongoDB.
We’ve written all of our server-side code in Django (Python). We use a pipeline architecture, where each request flows through a pipeline of steps, ranging from validation upfront to synchronization at the end. Each step takes just one argument — what we call the operation wrapper — does its work, and then it updates the wrapper for the next step to process. Each whole operation completes atomicly using Django’s excellent support for atomic transactions.
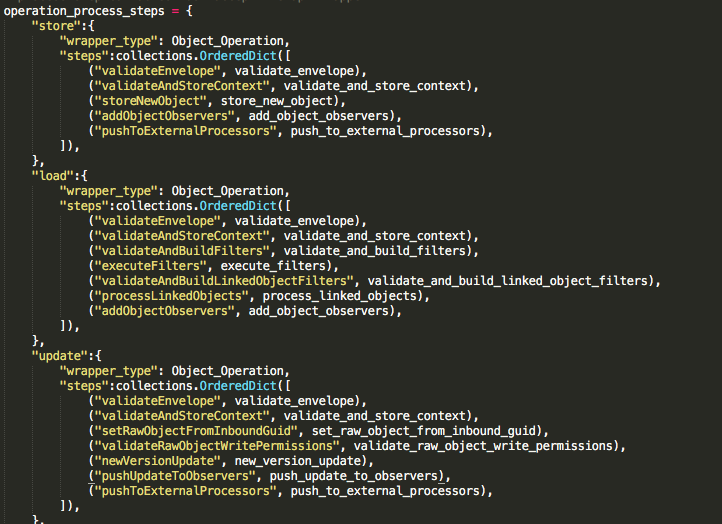
We use JSONB fields for the bodies of our CloudStore Objects, and we use regular SQL columns for the more structured data we use to query these documents so that loads can be fast. For example, metadata such as the Object’s type, unique identifier GUID, and creator ID can be stored as structured columns in Postgres. Most of the time in practice, querying is done via this metadata. We rarely find the need to filter by properties in the JSONB field, but that is also possible.
Permissioning is managed per object. It can be set at various levels, including read and write access being managed independently at the user, team, and organization level. Read permissioning is handled both at query time and again validated at “enveloping” time — when we take the list of objects returned by a query and generate JSON structure to be sent to the client. This provides two means of ensuring data is shown only to those with proper permissions to see it.
We use Redis and Celery for asynchronous operations, such as notifying observers of updates relevant to their subgraph. This allows synchronization operations to return back to the client without waiting for all of the subscribers to be called with updates, helping us scale.
We also use Redis, Celery, and AWS Lambdas for post-processing. Object post processing allows us to look for changes to certain types of objects and execute server side code in response. This can also be done for edges, so we can take some server-side action when a certain edge is set between two objects of pre-defined types.
We use Amazon’s API Gateway for our websockets. For now, we’re rolling our own client-side component that keeps the connections alive and the data fresh.
On the client side, the CloudStore framework is almost exclusively written in vanilla JavaScript. The only external package used is the lodash cloneDeep method, which is quite handy.
Our UI framework is Vue. Vue pairs very nicely with CloudStore, since templates and computed properties automatically update themselves when a change is made to CloudStore data, whether initiated locally or remotely. I built a small proxy adapter that overcomes Vue’s biggest reactivity blind spot: newly added properties. When the proxy detects that a property is being added to the object, it calls the Vue.$set(…) method automatically to notify Vue of the new property.
In the next post, I’ll describe some of the advantages we found with CloudStore, as well as some of the tradeoffs and open questions we have.